集成学习
集成学习就是将多个学习器集成在一起完成某个任务。集成学习可以有效的提升模型的性能,取得更好的结果。
一般来说,按照基本分类器之间的类型关系可以把集成学习方法划分为异态集成学习和同态集成学习。同态集成学习主要有Bagging和Boosting方法,异态集成学习有Stacking方法。集成学习要求基本的学习器错误率不能超过0.5,否则集成学习结果会提高错误率。
Bagging
Bagging就是让一个学习算法学习多轮,训练不同的模型。每一轮的训练集是从初始的训练集中随机取出n个数据进行训练,每次训练是相互独立的过程。对于训练得到的n个模型,分类问题可以采用投票方法,回归问题可以采用平均的方法来进行对测试样例的判断。
Voting 投票策略就是每个模型对测试样例进行投票,票数多的为测试的结果,如果出现投票数相同,要么随机选择一个,要么重新训练一个模型进行再分类。
Average 回归问题对所有的结果进行平均,一个改进的版本可以用加权的方式进行平均。例如A、B、C三个分类器得到的结果先进行排序,根据排序的不同赋予不同的权重
Boosting
Boosting利用一种迭代的方法,每一次训练的数据都在前一次训练的基础上产生。具体来说就是在每一次训练的时候会更加关心分类错误的样例,给这些分类错误的样例增加更大的权重。然后进行迭代训练,最后将这些分类器进行加权得到最后的分类器。但是boosting方法虽然会比bagging更容易得到好的效果,也会存在过拟合的问题。
Stacking
Stacking本质上是一种分层的结构,第一层通常是我们使用的不同基础模型,例如NN、决策树、KNN等。然后最后一层模型一般使用逻辑回归(LR)对这些模型进行进一步训练。
下图所示的是一个基本的二阶段stacking模型的示例。stacking的时候一般应选择相关性小的模型进行融合,以便让高层次的模型学到更多的信息,提高准确率。
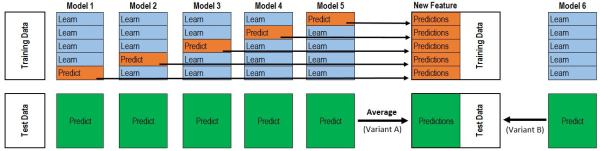
首先,在整个训练集通过五折交叉构造不同的训练集和验证集,第一阶段的每个分类器根据各自4份的训练集进行训练,并用验证集进行验证,将验证集的输出进行保存。将每个分类器的验证集的输出保存,并作为第二阶段分类器的输入。然后在整个训练集上训练第二阶段的分类器。第二阶段分类器的输出为训练集的标签(train_label)